
M2 Apprentissage et Algorithmes (M2A)
Master Mathématiques et Applications / Master Informatique – Sorbonne Université


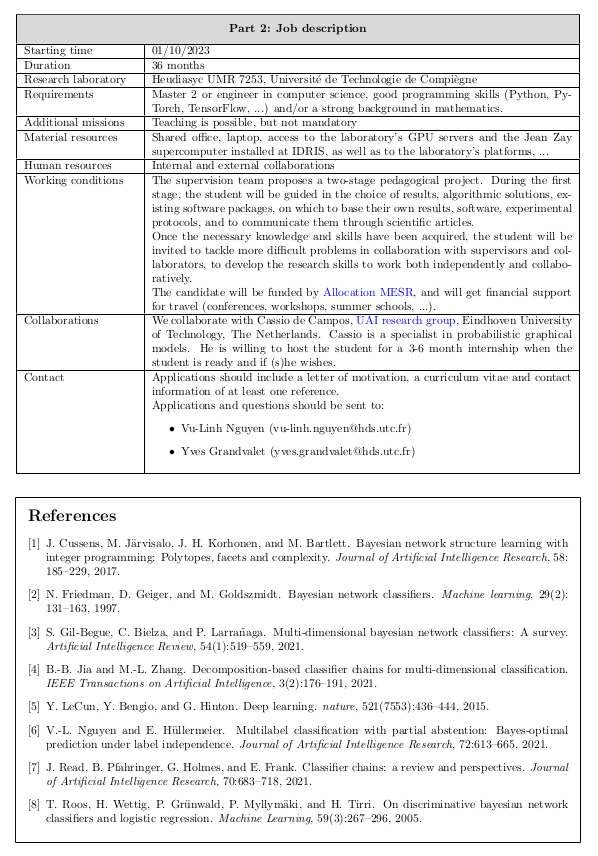
Deux offres de thèse.


Fully funded PhD Position available in Department of Biology and Department of Statistics, University of Oxford
Title: Evolutionary modelling to design optimal genetic control methods for crop diseases
Supervisors: Prof Tim Barraclough (Department of Biology), Prof Alison Etheridge (Statistics), Dr Jennie Castle (Economics)
This position is fully funded for stipend and international fees
Pests and disease account for losses of 30% of plant crops worldwide. Losses would be greater still without existing control methods, which focus on resistant varieties and chemical pesticides. Current approaches are unsustainable, however. Pests evolve to overcome any new control within 5 years or so, leading to a continual ‘arms race’ with agriscience needing to develop new varieties and chemicals. Also, pesticides have off-target effects on other species, which leads to environmental deterioration and a reduction in the resilience and productivity of crop systems themselves. Policy makers recognise the need to reduce chemical inputs and limit the land area devoted to intensive agriculture, but we currently lack ways to do that without losing more crops to plant disease. We need to develop more specific control measures with fewer off-target effects and that are more robust and agile for counter-acting the evolution of resistance.
New genetic methods such as CRISPR-Cas, RNAi sprays and gene drive open up the possibility of precision methods of controlling crop pests and diseases. But which genes or sets of genes should we target? Should we target them simultaneously or sequentially? How will the organisms evolve in response to the selection imposed by a given genetic control programme? And how will these methods interact with other components of crop management? This project will use mathematical models of evolving populations to develop design principles for future genetic control methods. It will then calibrate and evaluate their models against genome sequence data from evolutionary time-series of crop diseases. The work will combine mathematical models of gene network evolution in fluctuating environments, with whole-genome simulation studies tied to empirical datasets.
The project is suitable for a biologist with strong computing and quantitative skills, or for any quantitative scientist (e.g. mathematician, physicist, computer scientist) with interests in solving evolutionary biology and environmental problems. Training will be provided in modelling, computing, statistics, genomics and crop disease biology. The student will be co-supervised by Prof Tim Barraclough (Biology), Prof Alison Etheridge (Statistics).
The studentship is part of a project generating evolutionary time-series of crop pathogens and applying that knowledge to develop new control methods. Funded by Magdalen College’s Calleva Research Centre, the project forms an collaboration between Biology, Statistics and Economics at Oxford, and the National Institute for Agricultural Botany (NIAB) in Cambridge. A video describing the wider research programme is available here: https://www.youtube.com/watch?v=AsYv_aA4aVw
Funding: The project is funded by the Calleva Centre for Evolution and Human Science at Magdalen College (https://www.magd.ox.ac.uk/about-magdalen-college/research/calleva-research-centre/) It covers full funding for either a home or international student, including all fees and a yearly stipend at UKRI rates in 2023-2024 of £17,668.
Eligibility: Home or international students. For full entry requirements and eligibility information, please see https://www.ox.ac.uk/admissions/graduate/courses/dphil-biology
How to apply: The deadline for applications for this project entry is midday 14th April 2023. You can find the admissions portal and further information about eligibility and the DPhil in Biology Programme at https://www.ox.ac.uk/admissions/graduate/courses/dphil-biology
The successful applicant will receive a place at Magdalen College. https://www.magd.ox.ac.uk
Queries: Prof Tim Barraclough tim.barraclough@biology.ox.ac.uk
Prof Tim Barraclough
Professor of Evolutionary Biology,
Department of Biology, University of Oxford,
Tutorial Fellow, Magdalen College,
Telephone: +44 (0)1865 271109
https://www.biology.ox.ac.uk/people/professor-tim-barraclough
The Evolutionary Biology of Species Timothy G. Barraclough
Available from Oxford University Press: http://ukcatalogue.oup.com/product/9780198749752.do




PhD position in probability and statistics in the Department of Mathematics at Imperial College London starting October 2023 under the supervision of Dr. Riccardo Passeggeri. The position is for 3.5 years.
Please send me an email with your CV if interested to work on one of the topics of my research area:







